
Grace Li
UCLA Mathematics Department
Box 951555
Los Angeles, CA 90095-1555
Office: MS 6147
Office Hours: By appointment
E-mail: graceli at math dot ucla.edu
Gitlab: https://gitlab.com/graceli1
About Me
I am a 5th year PhD student in applied math at UCLA advised by Mason Porter. I will be graduating in June, 2024.
There are many different routes that could lead to applied mathematics, and I began the journey as a chemical engineer. Engineering became a mindset for me: a thought process to study problems from different angles, identify and weigh the importance of all relevant factors, and make appropriate simplifications to derive solutions. In my explorations of many applications including process design and controls, fluid dynamics, heat and mass transfer, material science, and quantum physics, the common link was my fascination with mathematical models and their utilization for quantitative analysis, pattern finding, and predictions. In taking a step back from pure mathematics, I came to comprehend its versatility and applicability, and arrived at the decision to pursue applied mathematics.
During my first two years as a graduate student, I witnessed the spread of misinformation and disinformation about the U.S. elections and the COVID-19 pandemic and how it influenced people. I also learned about researchers using mathematical modeling to address social inequities such as hiring bias, access to opportunities, and fair voting. My focus shifted towards social applications of mathematics and their exciting possibilities. Physical models and methods can be adapted or used as a source of inspiration to approach social problems.
Research Interests
Models of Opinion Dynamics
Humans are connected in numerous ways, and our many types of interactions with each other influence what we believe and how we act. To model how opinions spread between people or other agents, researchers in mathematics, physics, sociology, and other disciplines develop and study models of opinion dynamics. By constructing models of social connections and opinion formation, we can quantify the spread of ideas, characterize fragmentation and polarization of opinions, and study the growth of extremist beliefs. Much of my thesis research is about models of opinion dynamics, and I am interested in their complex dynamics, and their important applicability in the modern online landscape. These models can lead to insight on how to mitigate the unwanted spread of misinformation and disinformation (such as harmful “home remedies” during the COVID-19 pandemic) and how information campaigns from scientists and policy makers can better reach target audiences online.
Topics in Network Science
Networks are everywhere and can represent the relations in many applications including sociology, biology, physics, and many more. I am interested in developing and improving algorithms for community detection, finding "important" nodes, and label and link prediction. In today's world of increasingly available data, I also aim to develop computing techniques that scale to very large networks and apply them to interesting applications.
Additional Interests
Complex systems, network science, random graphs, social applications of mathematics and data science, machine learning, data-driven modeling and physicsResources
Here is an brief tutorial on gettings started with LaTeX. It can be viewed or downloaded from Overleaf and it is intended that you look at the .tex file and compare to the outputted pdf.
The Women in Math group at UCLA seeks to foster community and providing support for the women in the department. We are a trans-inclusive and nonbinary-inclusive group. We have put together some resources about how to apply to graduate school and what to expect.
Teaching
UCLA Teaching Assistant
Math 168 Introduction to Networks - Winter 2022, Spring 2022, Fall 2022Papers
Li, Grace J. and Porter, Mason A. ``Bounded-Confidence Model of Opinion Dynamics with Heterogeneous Node-Activity Levels.'' Physical Review Research, Vol. 5, No. 2: 023179, 2023. [Paper] [Code Repository]
Li, Grace J.*, Luo, Jiajie* & Porter, Mason A (*joint first author). [2022]. ``Bounded-Confidence Models of Opinion Dynamics with Adaptive Confidence Bounds.'' Preprint arXiv:2303.07563. 2023. [Paper] [Code Repository]
Selected Projects
Bounded-Confidence Models of Opinion Dynamics with Heterogeneous Activation Probabilities
Advised by Mason Porter
On social media, there tend to be individual accounts that initiate conversations, posts or other content more frequently. These heterogeneous levels of activity can impact the visibility of online content and what goes “viral”. However, existing research on models of opinion dynamics tends to focus on uniform probability distributions of activity. I developed a generalization of the Deffuant–Weisbuch bounded-confidence model of opinion dynamics that uses node weights to model agents in a social network with different probabilities of interacting. Using numerical simulations, I systematically investigated the effects of node weights and demonstrated that introducing them results in longer convergence times and more opinion fragmentation than in a baseline DW model. I also seek to apply my models to real-world social networks and to discover measures of social influence of nodes that account for both their node weight (representing sociability) and their position in a social network. My models are applicable to understanding the mechanisms in the spread of misinformation and disinformation, as well as identifying key individuals in this process and mitigating their harmful effects.
Bounded-Confidence Models of Opinion Dynamics with Adaptive Confidence
In collaboration with Jerry Luo and advised by Mason Porter
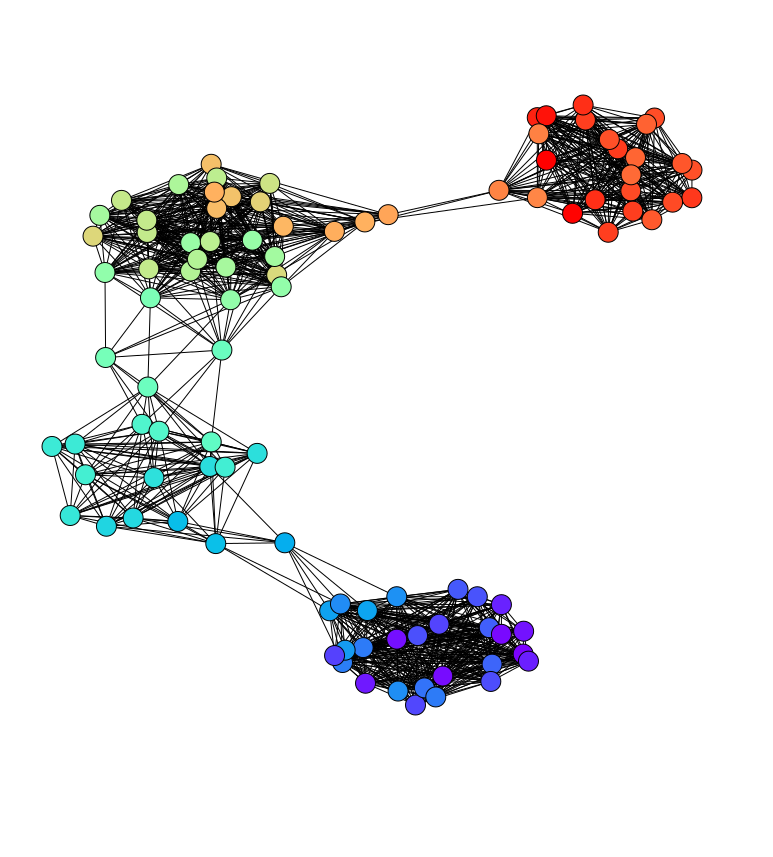
The ways that we form and change our opinions are influenced heavily by our social interactions. How much other people can influence us depends on many factors including the past interactions and levels of trust. In bounded-confidence models of opinion dynamics, pairs of agents only influence each other if their opinions differ by less than some “confidence bound” between them. We generalize the Hegselmann–Krause and Deffaunt–Weisbuch bounded-confidence models to incorporate adapative confidence bounds. This models time-dependence in the willingness of agents to listen to each other based on the nature of their prior interactions. We analytically and numerically explore the limiting behaviors of our models, including the confidence-bound dynamics, the formation of opinion clusters, and the time evolution of the time-dependent subgraph of the network with edges only between nodes that can currently influence each other. For a wide range of parameters, our models tend to yield less opinion fragmentation. We also observe novel consensus behaviors not present in the baseline Hegselmann–Krause and Deffaunt–Weisbuch models.
Twitter Response of Fortune-100 Companies to Racial Justice
In collaboration with Xia Li, Christopher Shriver, and Bertrand Stone, UCLA Applied Math Seminar, Spring 2021
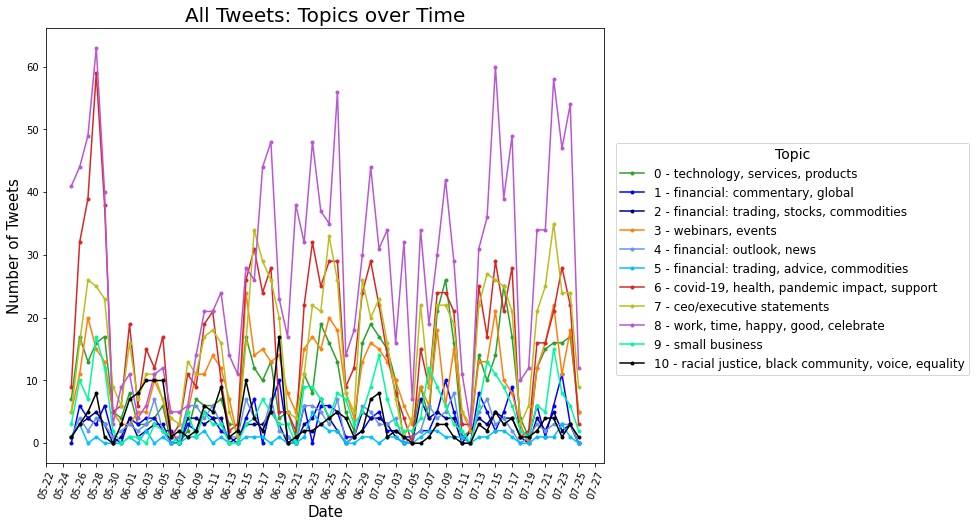
The summer of 2020 saw a marked increase in public expression of support for the Black Lives Matter (BLM) movement. As the movement gained momentum online, corporations faced social pressure to respond. We examined the relevant Twitter activity of Fortune 100 companies during this time period by analyzing the content of their tweets (data from Kevin McElwee), possible underlying networks between the companies, and patterns in their responses. I focused on topic analysis of the Fortune-100 tweets using non-negative matrix factorization (NMF). I identified topics including CEO statements, the COVID-19 pandemic, racial justice, celebrations, and investing, as well as which companies were most prominent (both in terms of number of tweets and user engagement) in those Twitter conversations. Using NMF on weekly time intervals and matching topics, I identified shifts over time for each topic. For example, the CEO statements shifted focus between addressing systemic racism, diversity, 2nd quarter earnings, and sustainability.
Social Forces in Twitter Networks of Senators
UCLA Statistics on Networks Course, Fall 2020
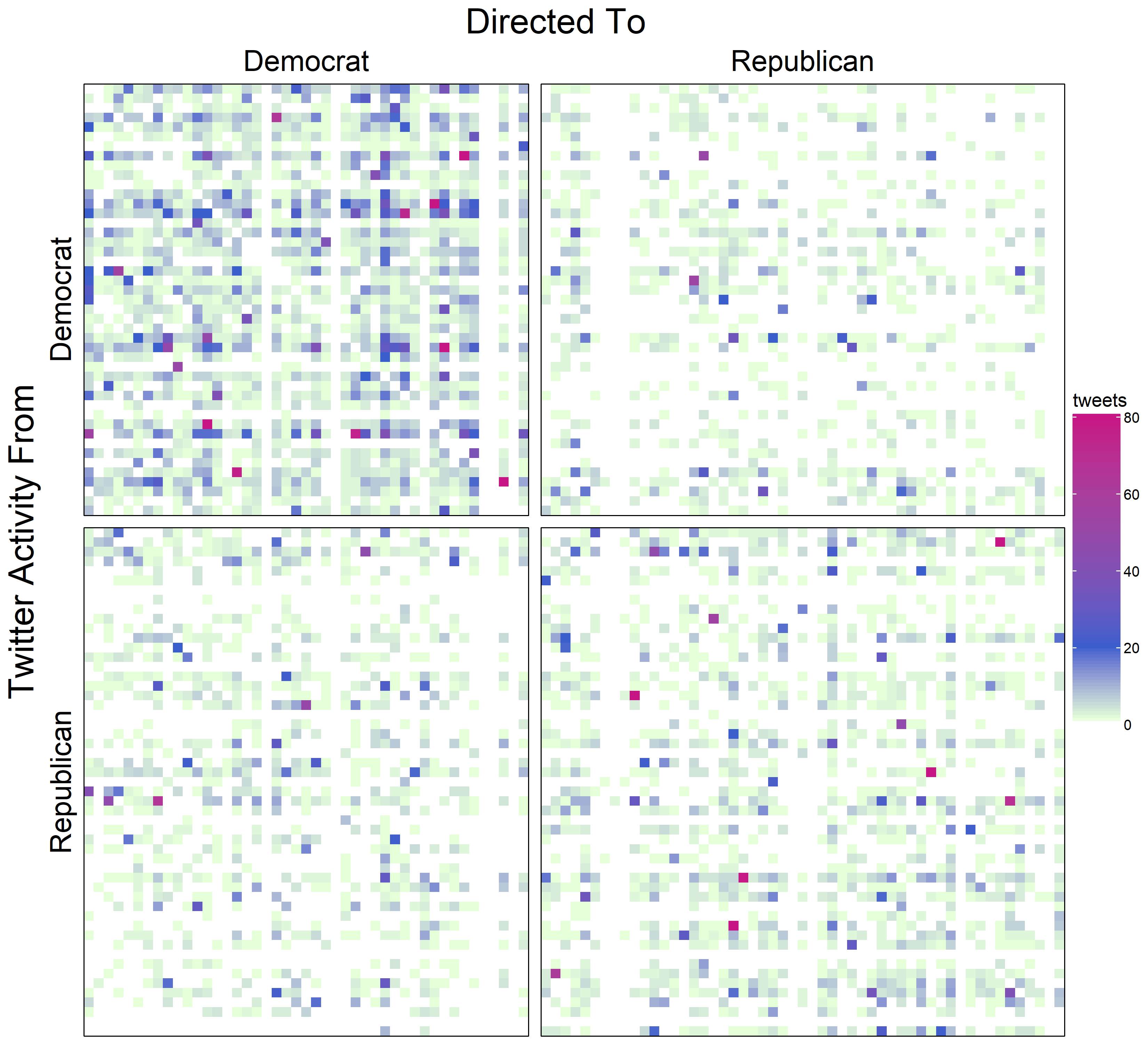
In the past decade, Twitter has become a popular platform for legislators to publicize their activities and views. To analyze the social forces influencing public online interactions between legislators, I constructed a network of senators in the 116th Senate with edges representing their interactions on Twitter. Using centrality measures from social network analysis, I identified central figures in the Twitter network. While some of the key senators held additional positions of power, many did not. Using exponential random graph models (ERGMs), I characterized the partisan influence on the network and found that the minority Democratic Party was more active on Twitter and a full nodemix ERGM model is needed for best fit of the partisan effects. Additional dyadic influences on the Senate network were reciprocity of ties, homophily for geographic region, and tendency to tweet those of similar age. I also considered the Democrat and Republican sub-networks separately to find within-party influences. Older Democrats tended to have more ties, while younger Republicans tended to have more ties. The Republicans also had significant region-based homophily and propensity for ties among senators with closer NOMINATE-1 scores representing voting-record partisanship. Both the Democrats and Republicans had a propensity to form transitive triads.
Analysis of Congressional Voting Data Using Clustering Methods
In collaboration with Kyung Ha, Jiayi Li, Blaine Talbut, and Thomas Tu, UCLA Applied Math Seminar, Spring 2021
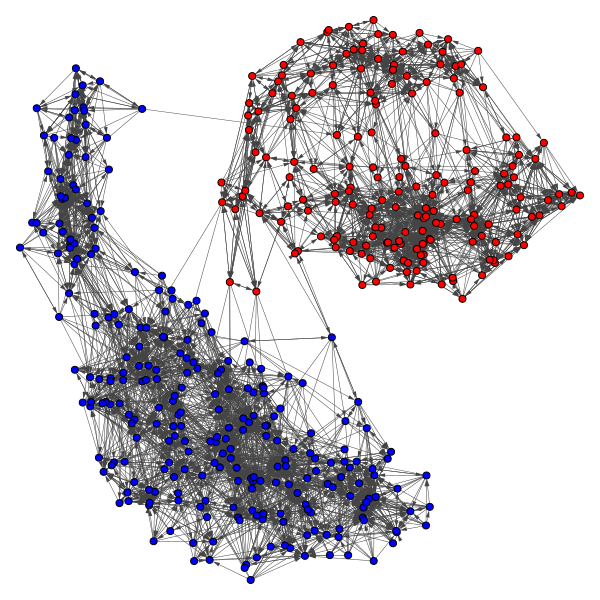
We utilized voting records in conjunction with clustering and community-detection algorithms to classify legislators into clusters by political stance. The underlying assumption is that legislators with more similar voting records have more similar political stances. We considered legislatures from multiple countries: the United States House of Representatives, German Bundestag, Legislative Council of Hong Kong, and South Korean National Assembly. For each legislature, we assessed how well different combinations of similarity functions and clustering algorithms could detect existing, known political parties. We were able to identify what larger political-party coalitions the independent legislators with no party affiliation were most aligned with. Additionally, we saw that number of clusters and modularity of the graph communities can be used to detect unity or division within a political party, and when there may be a shift in power within the legislature. In this project, I focused on investigating the use of different similarity functions to place legislators in a network with distances calculated from similarity of the roll-call votes.