To optimize, we take the derivative with respect to λ and set it equal to 0 to get
∂θ∂lnL(θ)=λnx−n=0⟹λ=X.
Problem 2
You throw a fair coin 30 times. You observe that 5 times it lands on heads, and 25 times it lands on tails. What is the maximum likelihood estimate for the probability that a single coin toss gives you heads?
Solution.
The MLE for a Bernoulli trial is p=X, where Xi=1 if the coin lands on heads and 0 otherwise. In our case, we have the observed value X=305=61, so
p=61.
Problem 3
Let y>0, θ>1. Define
f(x∣y,θ)=θyθx−θ−1,x≥y.
Show that f(x∣y,θ) is a probability density function.
Assume that y>0 is given. Let X1,…,Xn be i.i.d. random variables with probability density function f(x∣y,θ). Find the maximum likelihood estimator for θ.
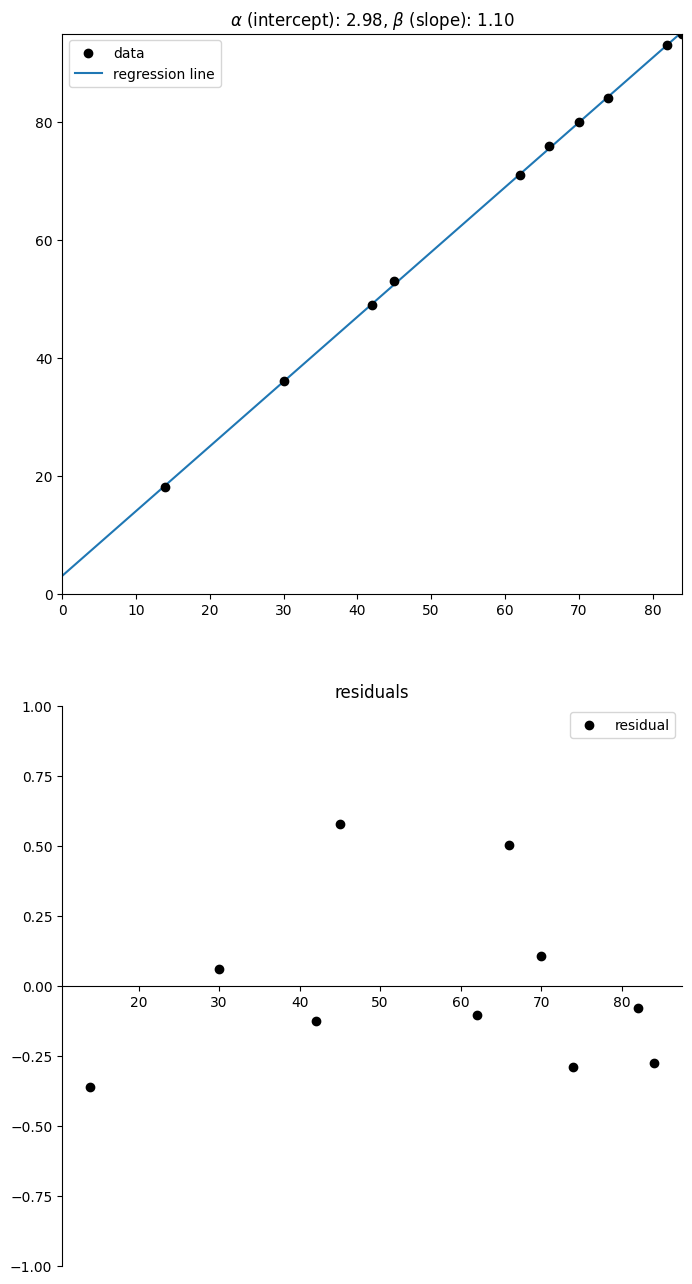
Calculate the least squares regression line for these data.
Plot the points and the least squares regression line on the same graph.
Draw the residuals plot. What does this tell you?
Find the maximum likelihood estimate for σ2.
Solution.
The least squares regression line is given by y=α+βx with square residuals σ2, where
αβσ2≈2.98≈1.10≈0.09
The residuals are relatively small, so this is a good fit.
Python Code
I used numpy since it's faster to type (and runs faster), but you can do the computations without it if you don't want to. However, using numpy makes plotting with matplotlib a bit easier.
from matplotlib import pyplot as plt
import numpy as np
x = np.array([62, 74, 66, 30, 84, 45, 14, 70, 82, 42])
y = np.array([71, 84, 76, 36, 95, 53, 18, 80, 93, 49])
x_bar = np.mean(x)
y_bar = np.mean(y)
beta_hat = np.sum((y - y_bar) * (x - x_bar)) / np.sum((x - x_bar) ** 2)
alpha_hat = y_bar - beta_hat * x_bar
sigma2_hat = np.mean((y - alpha_hat - beta_hat * x) ** 2)
# Or without numpy:# beta_hat = sum([(y[i] - y_bar) * (x[i] - x_bar) for i in range(n)]) / sum(# [(x[i] - x_bar) ** 2 for i in range(n)]# )# alpha_hat = y_bar - beta_hat * x_bar# sigma_hat_2 = sum([y[i] - alpha_hat - beta_hat * x[i] for i in range(n)]) / nprint(f"alpha_hat: {alpha_hat}") # 2.9788895969084805print(f"beta_hat: {beta_hat}") # 1.0987892865218194print(f"sigma2_hat: {sigma2_hat}") # 0.09218688976135175
fig = plt.figure(figsize=(8, 16))
# Plot sample and regression line
ax = fig.add_subplot(2, 1, 1)
ax.set_title(
f"$\\alpha$ (intercept): {alpha_hat:>.2f}, $\\beta$ (slope): {beta_hat:>.2f}"
)
ax.set_xlim(0, np.max(x))
ax.set_ylim(0, np.max(y))
ax.scatter(x, y, c="black", label="sample")
ax.axline((0, alpha_hat), slope=beta_hat, label="regression line", zorder=-1)
ax.legend()
# Plot residuals
ax = fig.add_subplot(2, 1, 2)
ax.set_title("residuals")
ax.spines["top"].set_visible(False)
ax.spines["right"].set_visible(False)
ax.spines["bottom"].set_position("zero")
ax.set_ylim(-1, 1)
ax.set_yticks(np.linspace(-1, 1, 9))
ax.scatter(x, y - (alpha_hat + beta_hat * x), c="black", label="residual")
ax.legend()
Problem 5
For α>0, β>0, the Beta distribution has probability density function
f(x∣α,β)=Γ(α)Γ(β)Γ(α+β)xα−1(1−x)β−1,x∈(0,1).
Find the method of moments estimator for α and β.
Solution.
This is a straight calculation. The mean and variance of a Beta distribution are
E[X]=α+βα,VarX=(α+β)2(α+β+1)αβ.
Note that
n1i=1∑n(xi−x)2=n1i=1∑nxi2+x2,
so when computing the method of moments estimator, we can just set
v=n1i=1∑n(xi−x)2=VarX
instead of using the second moment. This is only slightly easier, and the computations will be similar.